Stacked Capsule Autoencoders
Published:
Capsule Networks(CapsNet) have been growing in application and development ever since the radical breakthrough of Vector Capsules1. The fundamental idea behind colecting more information about the presence of an object in an image such as its pose, angle and depth remain a non-trivial open problem. CapsNet is a step forward in the direction and addresses the issue by spatially abstracting and taking into account rotational equivariance. This post is a review of the recent direction proposed the new Stacked Capsule Autoencoder paper2.
SCAE

So, what is a Stacked Capsule Autoencoder(SCAE)? The paper defines SCAE as an unsupervised capsule encoder which explicitely uses geometric relationships to reason about objects in an image. The SCAE consists of 2 stages- the Part Capsule Autoencoder (PCAE) and the Object Capsule Autoencoder (OCAE). The PCAE predicts presence and poses of objects by abstracting parts from the image and tried to reconstruct the images by arranging the abstracted part templates. The OCAE, on the other hand, predicts parameters of a few object capsules which are later used to reconstruct poses. The main contribution of SCAE is pose part-object abstraction as a means for pose estimation. Moreover, the unspuervised classification approach proves the ability of SCAE to associate different object capsules to different object capsules.
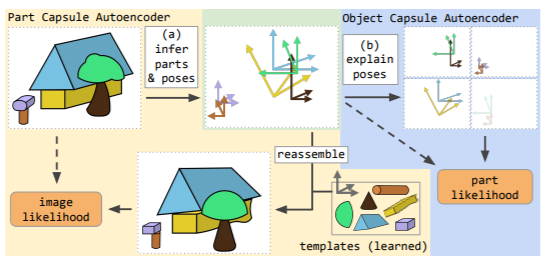
PCAE
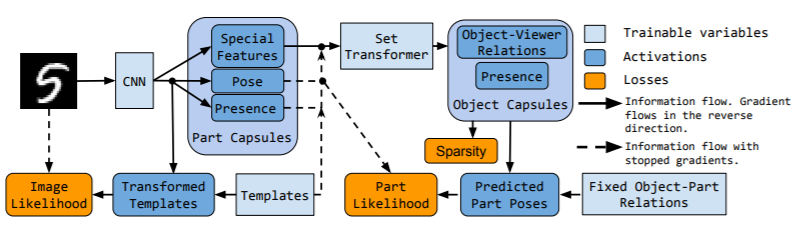
PCAE aims to explain the presence and geometrical relationship of parts in an image. It infers the relationship of the part to the viewer (their pose). PCAE explains the pose using a capsule consisting of six dimensions- 2 rotations, 2 translations, scale and shear. Additionally, each capsule consist of a presence variable $d_{m} \in [0,1]$ and a unique identity. The autoencoder consists of an encoder and a decoder. The encoder learns to infer poses and presences of different part capsules whereas the decoder learns an image template for each part. This is similar to the previous autoencoder architecture proposed using capsules[3]. If the capsule contains the part, the corresponding template is affine-transformed in order to yield the infered pose $T_{m}$. All the tranformed templates are later arranged into an image.
PCAE also makes use of special features to alter templates in an input-dependent manner. Here, the term input-dependent implies the usage of special features to predict color. These special feature also inform the OCAE about uniqueness of an image such as occlusion or relation to other parts. Each part capsule is used only once to reconstruct an image. This is done to avoid repeatability of same parts. Inference of part-capsule parameters is carried out using a CNN-based encoder followed by attention-based pooling. Attention-based pooling is a combination of global average pooling with bottom-up attention mechanism. The unique component of attention-based pooling is that it uses an additional channel $d+1$ which stores the softmax logits for attention. Finally, the image is modelled as a spatial Gaussian mixture composed of the pixels of the transformed templates as the centres of isotropic Gaussian components.
OCAE
The OCAE discovers objects from their parts and poses. It makes use of poses, special features and flattened templates as an input. Firstly, the part capsule probabilities are fed to the encoder, these are used to bias the transformer's attention mechanism. Secondly, the probabilities are used to weigh the log-likelihood so that log-likelihood of absent points are not taken into consideration. Additionally, gradient flow on all of OCAE's inputs is stopped except the special features in order to improve training stability and avoiding the problem of collapsing latent variables. Finally, the OCAE makes one candidate prediction per part. The OCAE is trained by maximizing the part-pose likelihood of the part-capsule likelihood.
Observing Diverse Capsule Presences
SCAE aim to maximize pixel part and object likelihoods. In order to motivate SCAE to use different set of part-capsules for different examples, sparsity and entropy constraints are imposed. These are described as followed-
Prior Sparsity - Intuitively, prior sparsity relates to the association of one object to one class/capsule. Assuming that training examples contain objects from different classes uniformly at random then each class would get a fixed number of capsules. This results in the summation of presence probabilities from each object capsule.
Posterior Sparsity - The within-example entropy of capsule posterior presence is minimized whereas the between-example entropy is maximized. However, the ablation study provided in the paper shows that auteoncoder is robust to these posterior entropy constraints.
References
[1]. Dynamic Routing Between Capsules
[2]. Stacked Capsule Autoencoders
[3]. T. Tieleman (2014). Optimizing Neural Networks That Generate Images. University of Toronto, Canada