Evolution-based Soft Actor Critic
Published:
Concepts and applications of Reinforcement Learning (RL) have seen a tremendous growth over the past decade. These consist of applications in arcade games, board games and lately, robotic control tasks. Primary reason for this growth is the usage of computationally efficient function approximators such as neural networks. Modern-day RL algorithms make use of parallelization to reduce training times and boost agent's performance through effective exploration giving rise to scalable methods, commonly referred to as Scalable Reinforcement Learning (SRL). However, a number of open problems such as approximation bias, lack of scalability in the case of long time horizons and lack of diverse exploration restrict the application of SRL to complex control and robotic tasks.
Evolution: The Scalable Revolution
Recent advances in RL have leveraged evolutionary computing for effective exploration and scalability. By making use of population-based policy search and reducing backpropagation, evolution-based techniques optimize policies in the weight space using the rewards as fitness metrics. OpenAI highlights the large-scale parallelizable nature of Evolution Strategies (ES). Performance of ES on continuous robotic control tasks in comparison to various gradient-based frameworks such as Trust Region Policy Optimization (TRPO) and Proximal Policy Optimization (PPO) have been found comparable. On the other hand, ES falls short of state-of-the-art performance resulting in local convergence and is extremely sensitive to mutation hyperparameters. An alternative to a pure evolution-based approach is a suitable combination of an evolutionary algorithm with a gradient-based method, referred to as Evolutionary Reinforcement Learning (ERL) . ERL makes use of selective mutations and genetic crossovers which allow weak learners of the population to inherit skills from strong learners while exploring. Such an approach is a suitable trade-off between sample efficiency and scalability but does not necessarily introduce mutation robustness. Thus, addressing scalability and exploration while preserving state-of-the-art performance and mutation robustness requires attention from a critical standpoint.
ESAC
We introduce Evolution-based Soft Actor Critic (ESAC), an algorithm combining ES with SAC for state-of-the-performance equivalent to SAC and scalability comparable to ES. ESAC abstracts exploration from exploitation by exploring policies in weight space using evolutions and optimizing gradient-based knowledge using the SAC framework. ESAC makes use of a novel soft winner selection function which carries out genetic crossovers in hindsight. ESAC also introduces the novel Automatic Mutation Tuning (AMT) which maximizes the mutation rate of ES in a small clipped region and provides significant hyperparameter robustness.
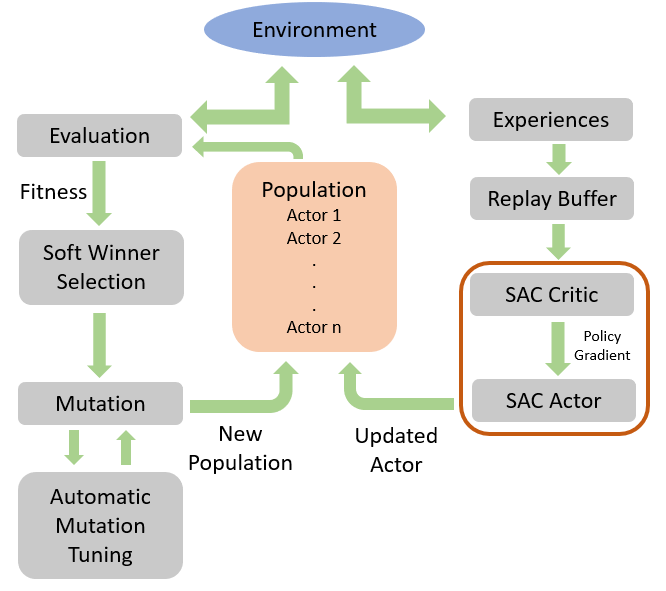
Automatic Mutation Tuning (AMT)
Instead of maximizing randomness in the policy space, we maximize it in the weight space. We automatically tune the deviation of the initial distribution. Mutation rate is updated at fixed timesteps in a forward-ascent manner in order to expand the search horizon of population. AMT motivates guided exploration towards the objective enabling the agent to maximize rewards as randomly as possible. AMT makes use of the SmoothL1 (Huber) loss function. The update rule is mathematically expressed as-
While exploring in weight space, the SmoothL1 loss tends to take up large values. This is indicative of the fact that the deviation between the winner and other learners of the population is significantly high. In order to reduce excessive noise from weight perturbations, we clip the update in a small region parameterized by a clip parameter. Suitable values for clip parameter range between 1e-6 to 1e^-2. The clipped update is mathematically expressed as-
Robust Policies
Combination of RL and evolutionary methods provides suitable performance on control benchmarks. It is essential to assess the behaviors learned by agents as a result of weight-space exploration. We turn our attention to observe meaningful patterns in agent’s behavior during its execution in the environment. More specfically, we aim to evaluate the robustness of ESAC scheme which promises efficacious policy as a result of effective exploration. We initialize a learned ESAC policy on the WalkerWalk task and place it in a challenging starting position. The Walker agent stands at an angle and must prevent a fall in order to complete the task of walking suitably as per the learned policy.\
Figure demonstrates the behavior of the Walker agent during its first 100 steps of initialization. The agent, on its brink of experiencing a fall, is able to gain back its balance and retain the correct posture for completing the walking task. More importantly, the agent carries out this manoeuvre within 50 timesteps and quickly gets back on its feet to start walking. This is an apt demonstration of robust policies learned by the ESAC agent. Dominant skill transfer arising from hindsight crossovers between winners and offsprings provisions effective exploration in weight space.







Scalability is the Key
Figure presents the scalable nature of ESAC equivalent to ES on MuJoCo locomotion tasks. Average wall-clock time per episode is reduced utilizing CPU resources which is found to be favourable for evolution-based methods. Moreover, the variation depicts consistency with the increasing number of members in the population indicating large-scale utility of the proposed method. A notable finding here is that although ESAC incorporates gradient-based backpropagation updates, it is able to preserve its scalable nature by making use of evolutions as dominant operations during the learning process. Reduction in the number of SAC updates by exponentially annealing the gradient interval allows ESAC to reduce computation times and simultaneously explore using AMT. However, the average episode time reaches a minimum value which is greater than the episode duration obtained by ES. This occurs as a result of the high probability of SAC updates early in training which is an essential requirement for avoiding local basins and sub-optimal convergence.
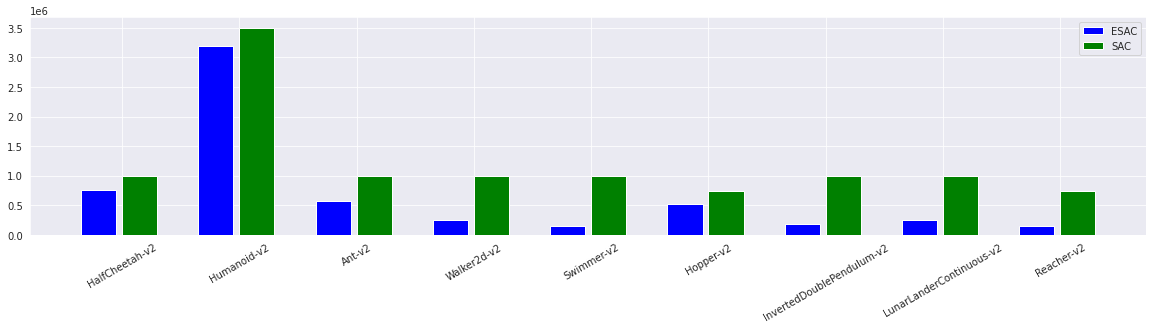
The main computation bottleneck in SAC arises from the number of backprop updates. This is tackled by exponentially annealing these updates and increasing winner-based evolutions and crossovers for transferring skills between SAC agent and ES offspings. ESAC executes lesser number of updates highlighting its computationally efficient nature and low dependency on a gradient-based scheme for monotonic improvement.
References
[1]. Evolution Strategies as a Scalable Alternative To Reinforcement Learning
[2]. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
[3]. Evolution-Guided Policy Gradient in Reinforcement Learning